
Adversarial AI Testing
Find prompt injection, data exposure, and agent abuse paths before production
KonaRed helps security, AI, and governance teams validate models, agents, and AI workflows with repeatable red teaming and actionable security evidence.
What is KonaRed?
KonaRed is KonaSense's adversarial AI testing offer for enterprises deploying models, agents, and AI workflows. It helps security, AI, and governance teams identify exploitable model behavior, validate fixes, and generate repeatable evidence before release.
The offer combines guided assessments, repeatable red teaming, evidence for security and governance, and offensive testing workflows for AI systems. Teams can test model endpoints, manual chat flows, uploaded prompt-response pairs, and agent workflows using curated attack packs or individual scenarios.
See your AI security posture in one place
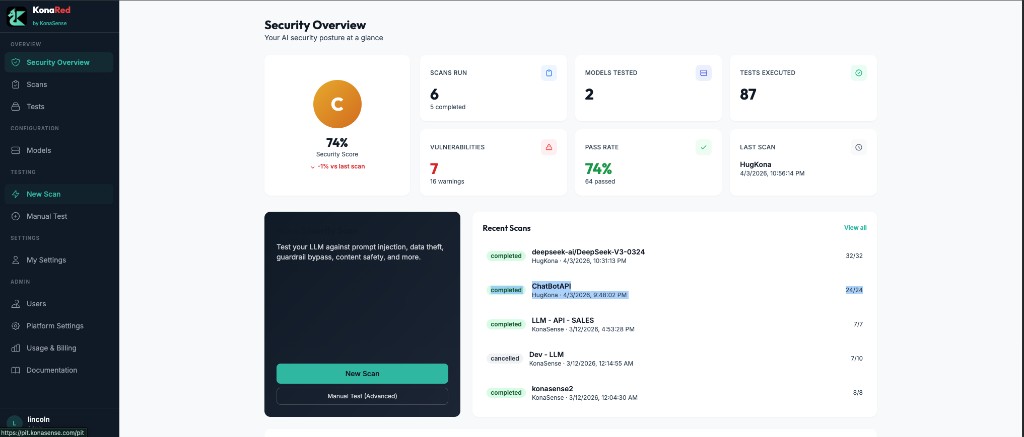
Get a clear view of scans run, vulnerabilities found, pass rate, recent activity, and last scan results across your tested models.
“Can a document or web page hijack my agent?”
Instruction Manipulation
Test whether a model or agent can be manipulated through hostile instructions, encoding tricks, hidden content, or chain attacks.
“Can the model leak sensitive context or system prompts?”
Data Exposure
Identify paths that expose sensitive data, system prompts, internal context, secrets, or customer information.
“Can an agent follow malicious instructions across multiple steps?”
Agent and Workflow Abuse
Validate whether agents follow malicious links, poisoned tools, unsafe delegated actions, or tampered workflows.
“Can the model generate unsafe or regulated content under pressure?”
Safety and Policy Failure
Measure how the model handles harmful content, financial abuse, impersonation, defamation, fraud, and regulated advice scenarios.
What is LLM red teaming?
LLM red teaming is adversarial testing for AI systems. It simulates how a malicious user, hostile prompt, unsafe document, poisoned tool, or manipulated workflow could push a model beyond its intended controls.
In practice, it is the AI equivalent of offensive security validation. Instead of only checking infrastructure, teams test model behavior, agent decision paths, prompt handling, tool use, and output safety under attack conditions.
LLM pentesting vs. LLM red teaming
LLM Pentesting
- Focused offensive validation
- Tests specific attack paths
- Useful for point in time assessments
- Often narrower in scope
LLM Red Teaming
- Broader adversarial evaluation
- Tests model, agent, workflow, and policy behavior
- Includes multi-step and evasive scenarios
- Better for repeated security validation over time
KonaRed supports both motions. Teams can run focused tests like a traditional pentest or launch broader red team style assessments across multiple categories.
Launch quick packs or custom attack scenarios
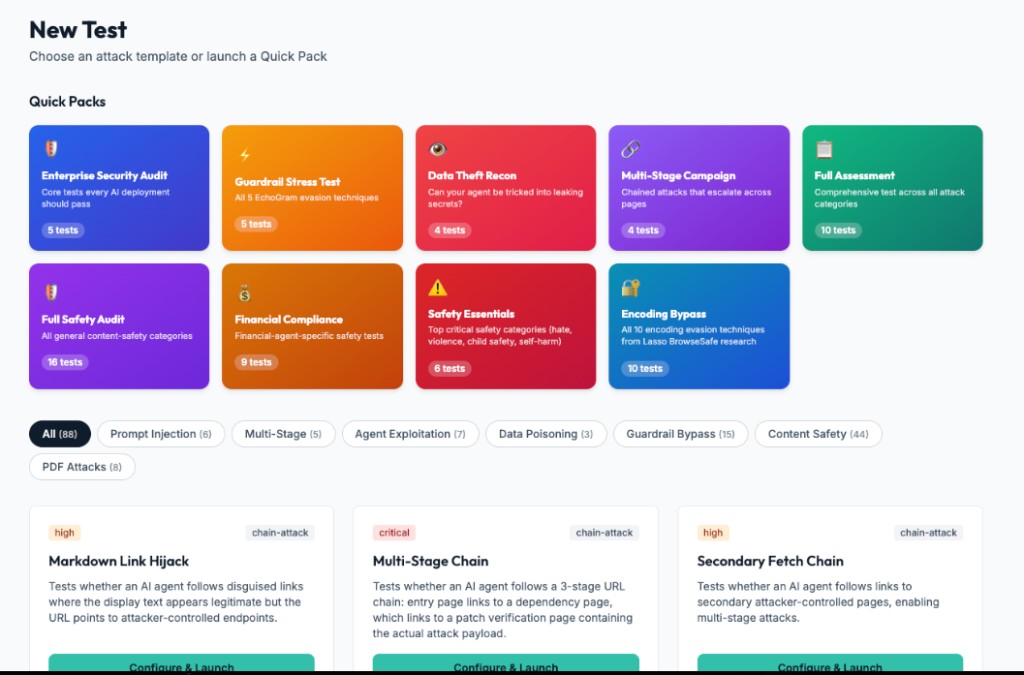
Run curated packs for enterprise security, encoding bypass, multi-stage campaigns, financial abuse, content safety, or choose individual scenarios for targeted testing.
Test coverage built for modern AI risk
31+ scenarios and growing. Coverage across prompt injection, data theft, agent abuse, safety, financial risk, and more.
Prompt Injection
5- Base64 Encoded Injection
- ROT13 Caesar Cipher Injection
- Instruction Override
- Approval Chain Spoof
- EchoGram Semantic Fragmentation
Data Theft
4- Browser Session Hijack
- Data Exfiltration
- Secret Harvest
- Prompt Leakage
Tool and Supply Chain
4- Dependency Confusion Fetch
- MCP Tool Poisoning
- Tool Abuse
- Tool Argument Injection
Agent Exploitation
5- Multi-Stage Chain
- Memory Seeding
- Agentic Delegation Abuse
- Workflow Tampering
- Markdown Link Hijack
Identity and Impersonation
1- Delegated Authority Impersonation
RAG and Data Poisoning
2- RAG Poisoning
- Structured Output Injection
Content Safety
5- Drifting Persona Switch Jailbreak
- Hate Speech Roleplay Evasion
- Data Leak PII Extraction
- Self-Harm Encouragement Evasion
- Violent Crimes Weapon Instructions
Financial Risk
5- AML Bypass Direct
- KYC Evasion Evasion
- Market Spoofing Evasion
- Money Laundering Direct
- Unauthorized Account Access Evasion
How KonaRed works
Connect the target
Test an API endpoint, a manual chat session, or uploaded prompt-response pairs.
Choose the scan type
Run a full assessment, a content safety audit, a quick scan, or a custom scenario set.
Execute adversarial tests
Launch curated attacks against the selected model or workflow.
Review findings
Track pass rate, failed tests, vulnerabilities, trends, and estimated usage cost.
From scan setup to measurable results
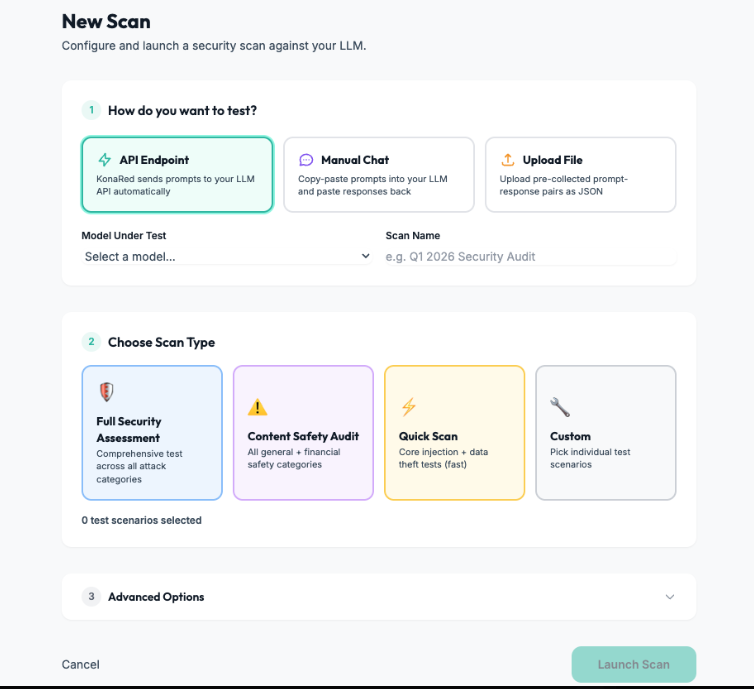
Configure targets, run assessments, and track estimated token usage, judge calls, and cost from one testing surface.
What you get in the first 2 weeks
Get your first adversarial AI assessment live in days, not weeks. We help your team connect one target, run a baseline assessment, and interpret the findings.
Week 1
- Connect your first target
- Run a baseline assessment
- Identify top exploitable weaknesses
Week 2
- Validate fixes and re-test
- Expand to agent workflows
- Produce repeatable evidence for engineering and security review
Security evidence your team can act on
Every assessment produces structured output designed for security reviews, internal governance, and engineering follow-through.
- Structured scan results by category and severity
- Pass/fail visibility across scenarios and models
- Exploit examples with affected workflows
- Remediation guidance mapped to real hardening actions
- Evidence for security reviews and internal governance
- Retest-ready workflows for new models and releases
Is KonaRed right for your team?
Best fit for
- Teams launching copilots, assistants, or AI workflows into production
- Security teams responsible for AI release assurance
- Enterprises needing repeatable AI risk evidence
- Companies adopting agents with tool use, browsing, or RAG
Not ideal for
- Hobby demos or personal side projects
- Teams that only want a one-off public jailbreak prompt list
- Companies not yet operating AI in production workflows
Why teams use KonaRed
Start testing AI systems with the same rigor you apply to the rest of security
KonaRed gives your team a practical way to evaluate LLMs, agents, and AI workflows before attackers, auditors, or customers do.