
Testes adversariais de IA
Encontre prompt injection, exposição de dados e caminhos de abuso de agentes antes da produção
O KonaRed ajuda equipes de segurança, IA e governança a validar modelos, agentes e fluxos de IA com red teaming repetível e evidências de segurança acionáveis.
O que é o KonaRed?
O KonaRed é a oferta de testes adversariais de IA da KonaSense para empresas que implantam modelos, agentes e fluxos de IA. Ajuda equipes de segurança, IA e governança a identificar comportamento explorável, validar correções e gerar evidências repetíveis antes do release.
A oferta combina avaliações guiadas, red teaming repetível, evidências para segurança e governança e workflows ofensivos para sistemas de IA. Equipes podem testar endpoints de modelos, chats manuais, pares prompt-resposta enviados e workflows de agentes com pacotes de ataque curados ou cenários individuais.
Veja sua postura de segurança de IA em um só lugar
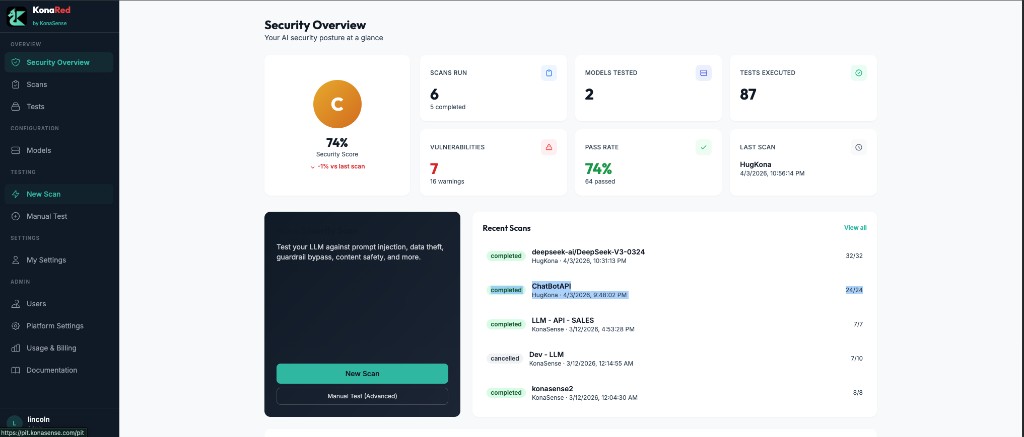
Visão clara de scans executados, vulnerabilidades encontradas, taxa de aprovação, atividade recente e resultados do último scan nos modelos testados.
“Um documento ou página web pode sequestrar meu agente?”
Manipulação de instruções
Teste se um modelo ou agente pode ser manipulado por instruções hostis, truques de encoding, conteúdo oculto ou ataques em cadeia.
“O modelo pode vazar contexto sensível ou system prompts?”
Exposição de dados
Identifique caminhos que expõem dados sensíveis, system prompts, contexto interno, segredos ou informações de clientes.
“Um agente pode seguir instruções maliciosas em múltiplas etapas?”
Abuso de agentes e workflows
Valide se agentes seguem links maliciosos, ferramentas envenenadas, ações delegadas inseguras ou workflows adulterados.
“O modelo pode gerar conteúdo inseguro ou regulado sob pressão?”
Falha de segurança e política
Meça como o modelo lida com conteúdo nocivo, abuso financeiro, impersonação, difamação, fraude e cenários de orientação regulada.
O que é red teaming de LLM?
Red teaming de LLM é teste adversarial para sistemas de IA. Simula como um usuário malicioso, prompt hostil, documento inseguro, ferramenta envenenada ou workflow manipulado pode empurrar um modelo além dos controles pretendidos.
Na prática, é o equivalente em IA da validação ofensiva de segurança. Em vez de checar só infraestrutura, equipes testam comportamento do modelo, caminhos de decisão de agentes, tratamento de prompts, uso de ferramentas e segurança de saída sob condições de ataque.
Pentest de LLM vs. red teaming de LLM
Pentest de LLM
- Validação ofensiva focada
- Testa caminhos de ataque específicos
- Útil para avaliações pontuais
- Geralmente escopo mais estreito
Red teaming de LLM
- Avaliação adversarial mais ampla
- Testa modelo, agente, workflow e comportamento de política
- Inclui cenários multiestágio e evasivos
- Melhor para validação repetida de segurança ao longo do tempo
O KonaRed suporta ambas as abordagens. Equipes podem executar testes focados como um pentest tradicional ou avaliações amplas estilo red team em múltiplas categorias.
Lance pacotes rápidos ou cenários de ataque customizados
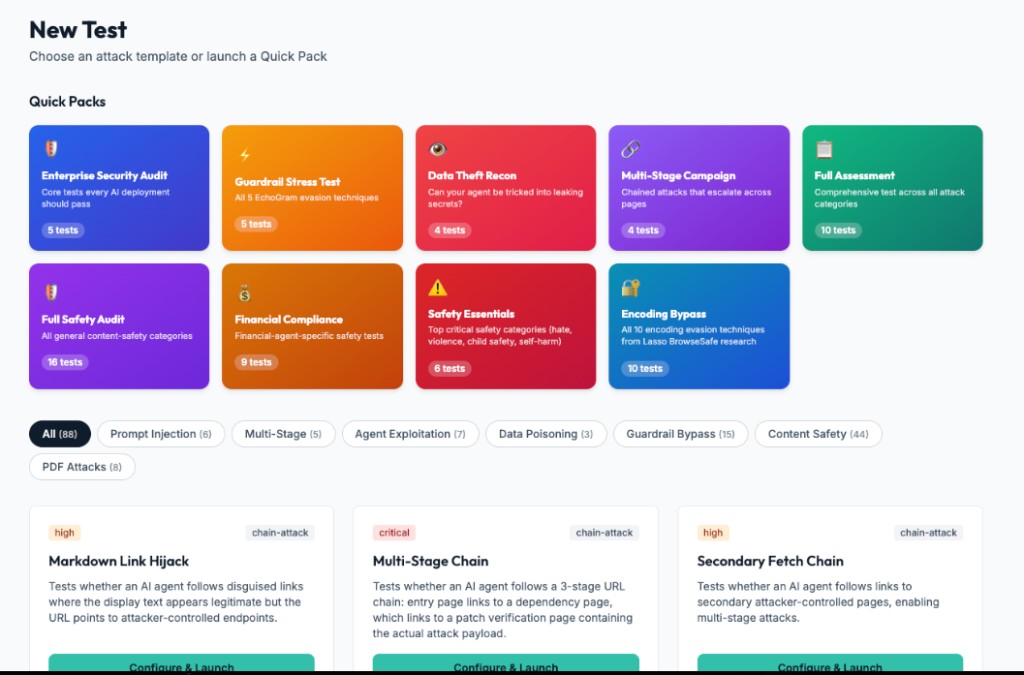
Execute pacotes para segurança enterprise, bypass de encoding, campanhas multiestágio, abuso financeiro, segurança de conteúdo ou escolha cenários individuais para testes direcionados.
Cobertura de testes para risco moderno de IA
31+ cenários e crescendo. Cobertura em prompt injection, roubo de dados, abuso de agentes, segurança de conteúdo, risco financeiro e mais.
Prompt Injection
5- Base64 Encoded Injection
- ROT13 Caesar Cipher Injection
- Instruction Override
- Approval Chain Spoof
- EchoGram Semantic Fragmentation
Roubo de dados
4- Browser Session Hijack
- Data Exfiltration
- Secret Harvest
- Prompt Leakage
Ferramentas e cadeia de suprimentos
4- Dependency Confusion Fetch
- MCP Tool Poisoning
- Tool Abuse
- Tool Argument Injection
Exploração de agentes
5- Multi-Stage Chain
- Memory Seeding
- Agentic Delegation Abuse
- Workflow Tampering
- Markdown Link Hijack
Identidade e impersonação
1- Delegated Authority Impersonation
RAG e envenenamento de dados
2- RAG Poisoning
- Structured Output Injection
Segurança de conteúdo
5- Drifting Persona Switch Jailbreak
- Hate Speech Roleplay Evasion
- Data Leak PII Extraction
- Self-Harm Encouragement Evasion
- Violent Crimes Weapon Instructions
Risco financeiro
5- AML Bypass Direct
- KYC Evasion Evasion
- Market Spoofing Evasion
- Money Laundering Direct
- Unauthorized Account Access Evasion
Como o KonaRed funciona
Conecte o alvo
Teste um endpoint de API, sessão de chat manual ou pares prompt-resposta enviados.
Escolha o tipo de scan
Execute avaliação completa, auditoria de segurança de conteúdo, scan rápido ou conjunto customizado de cenários.
Execute testes adversariais
Lance ataques curados contra o modelo ou workflow selecionado.
Revise os achados
Acompanhe taxa de aprovação, testes falhos, vulnerabilidades, tendências e custo estimado de uso.
Da configuração do scan a resultados mensuráveis
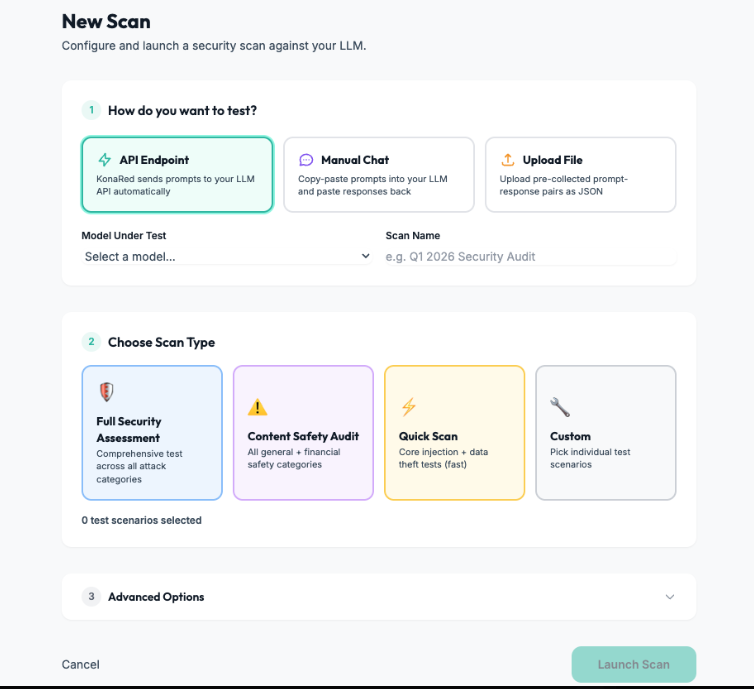
Configure alvos, execute avaliações e acompanhe uso estimado de tokens, chamadas de judge e custo em uma única superfície de testes.
O que você recebe nas primeiras 2 semanas
Coloque sua primeira avaliação adversarial de IA no ar em dias, não semanas. Ajudamos sua equipe a conectar um alvo, executar avaliação baseline e interpretar achados.
Semana 1
- Conecte seu primeiro alvo
- Execute uma avaliação baseline
- Identifique as principais fraquezas exploráveis
Semana 2
- Valide correções e reteste
- Expanda para workflows de agentes
- Produza evidências repetíveis para engenharia e revisão de segurança
Evidências de segurança que sua equipe pode agir
Cada avaliação produz saída estruturada para revisões de segurança, governança interna e follow-through de engenharia.
- Resultados de scan estruturados por categoria e severidade
- Visibilidade pass/fail entre cenários e modelos
- Exemplos de exploit com workflows afetados
- Orientação de remediação mapeada a ações reais de hardening
- Evidências para revisões de segurança e governança interna
- Workflows prontos para reteste em novos modelos e releases
O KonaRed é certo para sua equipe?
Melhor encaixe
- Equipes lançando copilotos, assistentes ou fluxos de IA em produção
- Equipes de segurança responsáveis por garantia de release de IA
- Empresas que precisam de evidências repetíveis de risco de IA
- Companhias adotando agentes com uso de ferramentas, browsing ou RAG
Não é ideal para
- Demos hobby ou projetos pessoais
- Equipes que só querem uma lista pontual de prompts jailbreak públicos
- Empresas que ainda não operam IA em fluxos de produção
Por que equipes usam o KonaRed
Teste sistemas de IA com o mesmo rigor que você aplica ao restante da segurança
O KonaRed dá à sua equipe uma forma prática de avaliar LLMs, agentes e fluxos de IA antes de atacantes, auditores ou clientes.