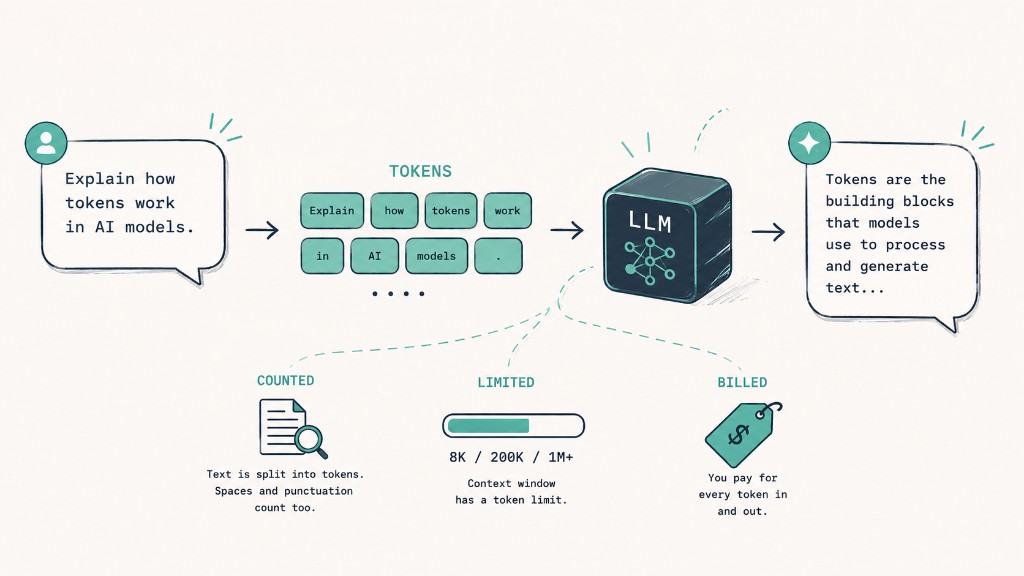
Every time you talk to Claude, ChatGPT, or any other model, what goes in and what comes out is billed in a unit called a token. It is not a word. It is not a character. It is something in between, and understanding exactly what it is has a direct impact on what you pay, what fits in the context window, and how the model behaves.
A token is the fundamental processing unit of a Large Language Model. The model never sees the text you wrote. It sees a sequence of integers, where each number represents a previously catalogued piece of text. Those pieces are the tokens, and the catalogue is the model's vocabulary.
The right question is not "what is a token". The right question is: how does text turn into numbers, how much does it cost, and why are the request and the response counted separately? That is what this post answers.
A token is not a word. It is not a character. It is something in between.
The rule of thumb used across the industry is: 1 token is roughly 0.75 English words, or about 4 characters. But that is just a rough average. Tokens can be whole words, parts of words (subwords), single characters, or even whitespace.
Here it is in practice. Consider the sentence Hello, tokenization is fun. This is how the GPT-4 tokenizer (the tiktoken library, cl100k_base encoding) splits it:
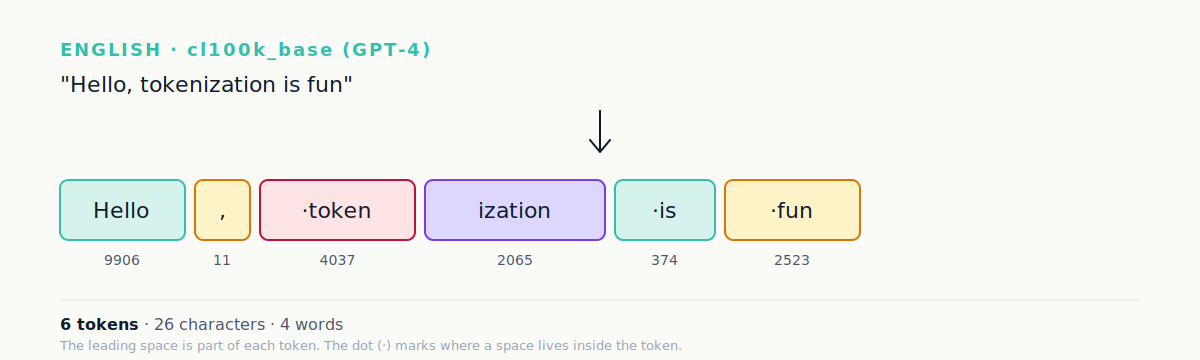
Notice three things. First, tokenization became two tokens: token and ization. Second, the leading whitespace before token is part of the token, not separate. Third, the comma is a token on its own.
Now the same idea in Portuguese. The phrase O modelo divide o texto em pedacos, which translates "The model splits text into pieces", tokenizes very differently:

Same meaning, 50 percent more tokens in Portuguese in this example. Many non-English prompts consume more tokens than equivalent English prompts, but the gap depends on the tokenizer, language, script, and writing style. Measure with the target model's tokenizer before pricing production usage. In our cl100k_base tests on a realistic paragraph of prose, Portuguese used about 1.46x the tokens of equivalent English prose. Newer tokenizers like o200k_base (GPT-4o and GPT-5.x) compress non-English text 20 to 50 percent better, but multilingual prompts still need measurement.
How text becomes a token: the BPE algorithm in 60 seconds
Many modern LLMs (GPT, Claude, Llama, Mistral, DeepSeek) use Byte Pair Encoding (BPE) or BPE-family subword tokenizers. It was invented by Philip Gage in 1994 as a data compression technique, published in The C Users Journal. In 2016, Sennrich, Haddow and Birch adapted it for NLP tokenization in their ACL paper on neural machine translation, and since then it has become the standard.
The core idea is absurdly simple:
- Start with individual characters. Every character in the alphabet becomes an initial token. The vocabulary starts with the 256 raw bytes (or basic Unicode characters).
- Count the most frequent adjacent pairs. The algorithm scans the entire training corpus and identifies which pair of adjacent characters appears most often. For example, t+h in English appears millions of times.
- Merge the most frequent pair into a new token. The pair th becomes a single token, added to the vocabulary. Every occurrence of t+h in the corpus is replaced with th.
- Repeat until the target vocabulary size is reached. The process runs tens of thousands of iterations. Whole words like the, and, tion emerge naturally as single tokens because they are frequent. Rare words remain split into smaller pieces.
The result is a vocabulary with tens of thousands of entries. The cl100k_base used by GPT-4 has 100,256 tokens. The o200k_base from GPT-4o has 199,997. Llama 4 has 202,048. DeepSeek V3 has 129,280.
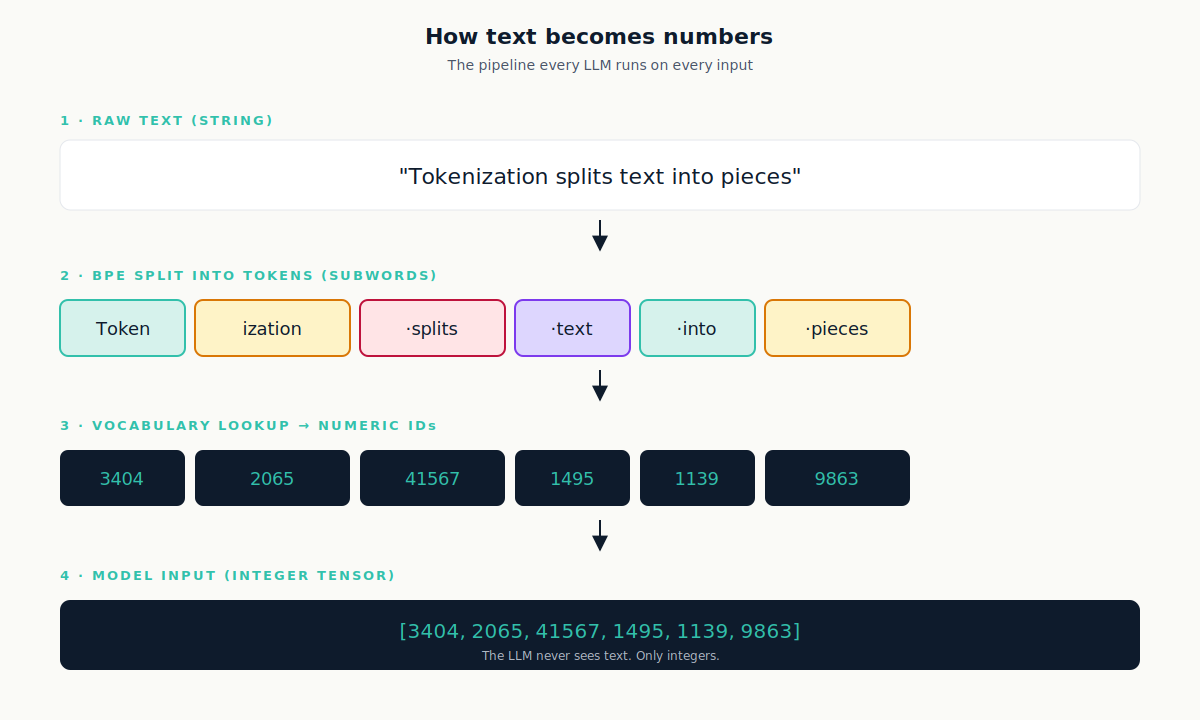
The important point is this: the vocabulary is fixed after training. It is part of the model. That is why every model has its own tokenizer, and the same sentence can produce different token counts across models. GPT-4 and Claude use distinct tokenizers. Claude Opus 4.7 in fact shipped with a new tokenizer that can produce up to 35 percent more tokens for the same input text compared to Opus 4.6, according to Anthropic's own pricing documentation.
Yes, request and response are billed separately. And at different prices.
This is the part that surprises most people starting out. When you send a message to an LLM via API, two kinds of tokens are counted:
- Input tokens (request). Everything you send. Your prompt, the conversation history in multi-turn chats, the system prompt, instructions, attached documents, tool definitions, and anything else inside the payload.
- Output tokens (response). Everything the model generates. Each output token is produced one at a time, autoregressively, until the model emits a special end-of-sequence token or hits the output cap.
And yes, they have different prices. Output almost always costs more than input, typically 2 to 6 times more across current frontier models. The reason is simple: generating tokens is computationally more expensive than reading them, because each new token requires a full forward pass through the model conditioned on every previous token.
Actual prices in May 2026
| Model | Input / 1M | Output / 1M | Context / output |
|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 | 1M / 128K out |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M / 64K out |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K / 64K out |
| GPT-5.5 standard short context | $5.00 | $30.00 | 1,050,000 / 128K out |
| GPT-5.5 standard long context, >272K input | $10.00 | $45.00 | 1,050,000 / 128K out |
| Gemini 3.1 Pro Preview, ≤200K prompt | $2.00 | $12.00 | 1M / 64K out |
| Gemini 3.1 Pro Preview, >200K prompt | $4.00 | $18.00 | 1M / 64K out |
| DeepSeek V4 Pro promo through May 31, 2026 | $0.435 | $0.87 | 1M / 384K out |
| DeepSeek V4 Pro post-promo adjusted price | $1.74 | $3.48 | 1M / 384K out |
| DeepSeek V4 Flash | $0.14 | $0.28 | 1M / 384K out |
Sources: Anthropic pricing and context docs, OpenAI GPT-5.5 model docs, Google AI Gemini API pricing, Google Gemini 3.1 Pro model card, and DeepSeek API pricing. GPT-5.5 applies 2x input and 1.5x output for the full session when prompts exceed 272K input tokens. Prices may vary by region and reseller (Bedrock, Vertex AI, Foundry).
A concrete cost calculation
Suppose you are using Claude Opus 4.7 to review a technical document:
System prompt: 800 tokens
Attached document: 12,000 tokens
User prompt: 50 tokens
Conversation history: 2,500 tokens
-------------
TOTAL INPUT: 15,350 tokens
Model response: 1,800 tokens
-------------
TOTAL OUTPUT: 1,800 tokens
COST:
Input: 15,350 / 1,000,000 x $5.00 = $0.07675
Output: 1,800 / 1,000,000 x $25.00 = $0.04500
-------
Total for this interaction: = $0.12175Pay attention to one thing: the input is more than 8 times larger in tokens than the output, but the output still matters on the bill. Output is priced much higher than input, so even a shorter response can represent a large share of the bill. In this example, output is only 12% of the token volume but about 37% of the cost. Long responses, code generation, and reasoning modes (reasoning tokens) can easily inflate the bill.
Heads up: models with reasoning modes (Claude Opus 4.7 with extended thinking, GPT-5.5 reasoning, Gemini 3.1 thinking) generate reasoning tokens internally before the visible response. These are billed as output, but you do not see their content. A single query can consume 20,000 or more reasoning tokens. Monitor the usage field in the response.
The context window: the hard limit no one can exceed
Every model has a context window, which is the maximum number of tokens (input + output) it can process in a single request. A model cannot process more than its effective context window in one generation; providers differ on whether they reject upfront or stop generation at the limit. For example, Anthropic notes that Claude 4.5+ may accept a request and later stop with model_context_window_exceeded, while earlier models may return validation errors.
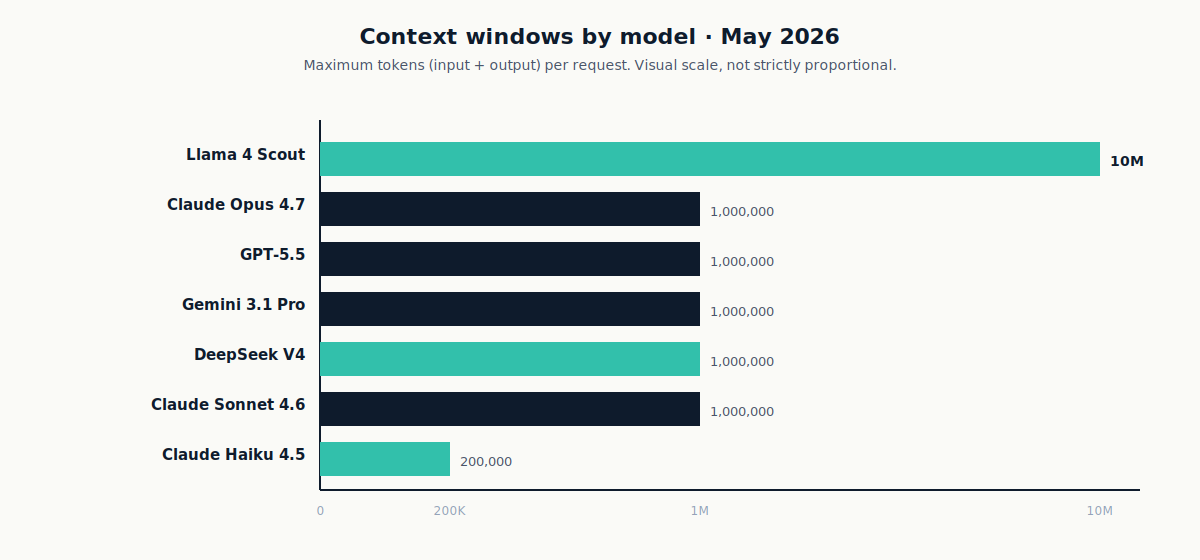
For practical reference:
- 1 page of prose, around 500 to 700 tokens.
- A 300-page book, around 150,000 to 200,000 tokens.
- The complete works of Shakespeare (884,000 words), around 1.1 to 1.3 million tokens.
- 1 hour of audio transcript: roughly 9,000 to 16,000 tokens depending on speaking rate.
- A medium codebase, between 50,000 and 500,000 tokens.
A 1 million token context window holds about a 1,500-page book, or most (but not all) of Shakespeare. But beware: a large context is not free. The more tokens in the input, the slower the model and the more KV cache memory you consume. Some providers charge long-context premiums. GPT-5.5 moves to higher rates above 272K input tokens, and Gemini 3.1 Pro Preview moves to higher rates above 200K prompt tokens. Anthropic's first-party Claude API currently includes the full 1M context for Opus 4.7, Opus 4.6, and Sonnet 4.6 at standard pricing.
What this actually means in production
Five concrete implications for anyone running LLMs in production:
- Multilingual usage needs measurement. If your app serves users in Portuguese, Spanish, or non-Latin scripts, token counts can run higher than equivalent English under the same tokenizer. Measure with the target model before you set customer pricing.
- Output is disproportionately expensive. Always set max_tokens. Ask for concise responses in the system prompt. Do not generate decorative markdown if you only need the data. Long or reasoning-heavy outputs can dominate the bill even when input volume is larger.
- Prompt caching is worth gold. Anthropic, OpenAI and Google all offer prompt caching with up to 90 percent discount on reused tokens. If you send the same system prompt or document across calls, cache it.
- Reasoning tokens count. In models with reasoning modes, monitor usage. A call can generate thousands of invisible tokens. Use reasoning mode only when the problem truly requires it.
- Do not trust crude estimates. The "1 token equals 0.75 words" rule breaks for code, JSON, non-Latin languages, and text heavy in numbers or symbols. Count properly before assuming a cost.
In one line
A token is the unit the model actually processes, typically a 3 to 4 character subword in English. Both what you send and what the model returns are billed, with output usually costing 2 to 6 times more than input.